Sekim
||
haesslich schrieb:Sekim schrieb:Beim samplen (Probennehmen) wird ja ein diskreter Wert pro Zeitpunkt generiert, deshalb muss die Genauigkeit der Abbildung des ursprünglich kontinuierlichen Verlaufs von ihrer Frquenz abhängen.Es gibt also auch immer "Informationslücken", außer die Samplefrequenz wäre unendlich hoch.
nein. das ist ein trugschluss, auf den man nur all zu leicht hereinfällt.
perfektes sampling und perfekte rekonstruktion SIND MÖGLICH. ohne, dass es "infromationslücken" gibt. unter zwei bedingungen:
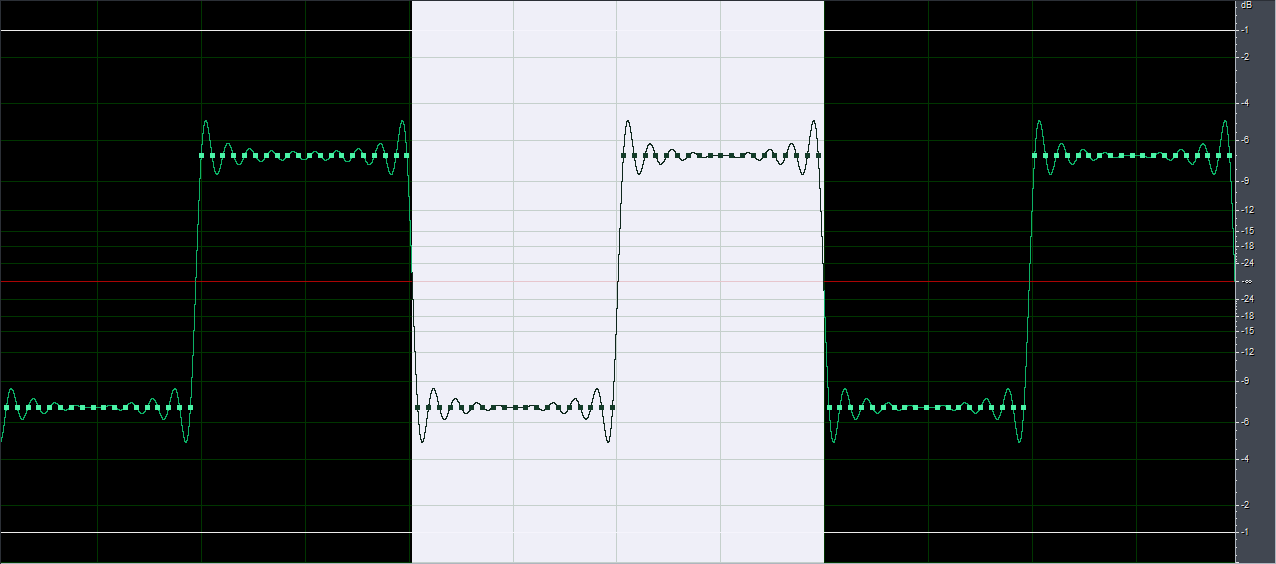
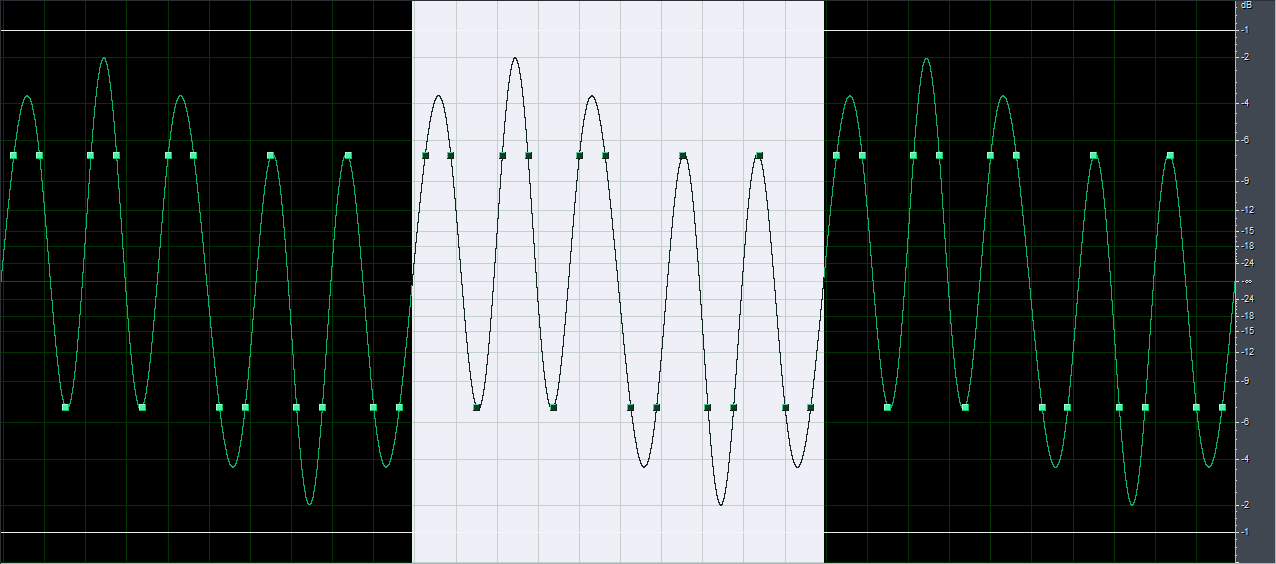
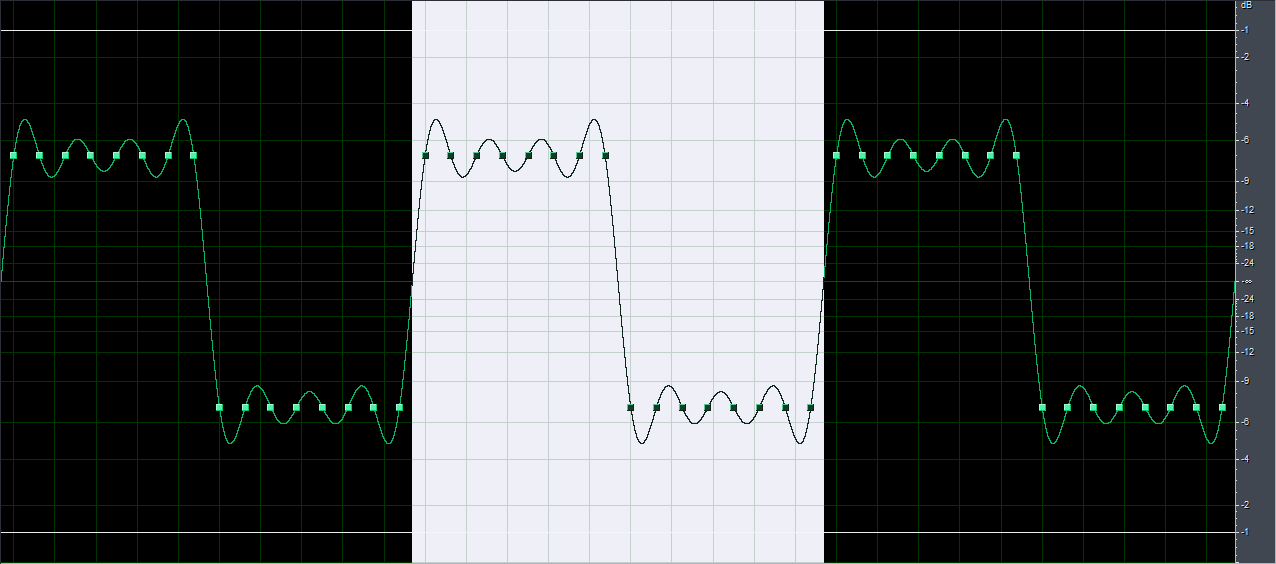
1. du hälst das "nyquist-shannon-abtast-theorem" ein. d.h. die höchste frequenz, die in deinem signal vorkommt, ist kleiner als die hälfte der samplingfrequenz.
2. du hast die möglichkeit zur perfekten rekonstruktion indem du z.b. unendlich delay bei der D/A wandlung in kauf nimmst.
das erste regel betrifft den weg von A nach D. das ist in der regel ziemlich gut möglich.
das zweite regel, von D nach A, wird, wie ich oben geschrieben habe, ziemlich gut approximiert durch moderne D/A wandler. sogar so gut, dass man selbst zwischen high end wandlern und consumer wandlern keinen unterschied mehr messen kann, und schon gar nicht hören kann.
grob gesagt ja. im detail neinOben fiel das Wort "Rekonstruktionsfilter", das hört sich nach einem Ansatz an,wieder Kontinuität zu erzeugen und gleichzeitig auch die "Lücken" zu schließen?")
Vielen Dank, auch Tim Kleinerts Beitrag und sein Wikipedialink zu Rekonstruktionfiltern sind für mich sehr hilfreich!
Alles Gute